Safe Words vs. Safe Actions
Your AI agent won’t write you a ransom note. It will, however, quietly rewrite your access control list if you ask nicely enough.

I need to tell you about a research paper that landed in my feed this week, and I want to start with the reason I’m writing about it at all.
Luiza Jarovsky, PhD Co-founder of the AI, Tech & Privacy Academy and author of a newsletter with 95,000 subscribers, flagged it with a post that read: “Another super innovative paper on agentic AI, this time focused on a new safety benchmark: Boiling the Frog. Bookmark it.” She was right. Bookmark it. And then read this.
The paper is called “Boiling the Frog: A Multi-Turn Benchmark for Agentic Safety,” authored by Piercosma Bisconti Lucidi, Matteo Prandi, Federico Pierucci, Federico Sartore, Enrico Panai, Laura Caroli, Yue Zhu, Adam Leon Smith, Luca Nannini, Marcello Galisai, Susanna Cifani, Francesco Giarrusso, Marcantonio Bracale Syrnikov, and Daniele Nardi — a large and impressive team doing some of the most careful agentic safety work I’ve seen published this year. Serious props to all of them. Link to the full paper here.
Now let me tell you why it matters to you.
There’s a hole in AI safety the size of your entire production environment
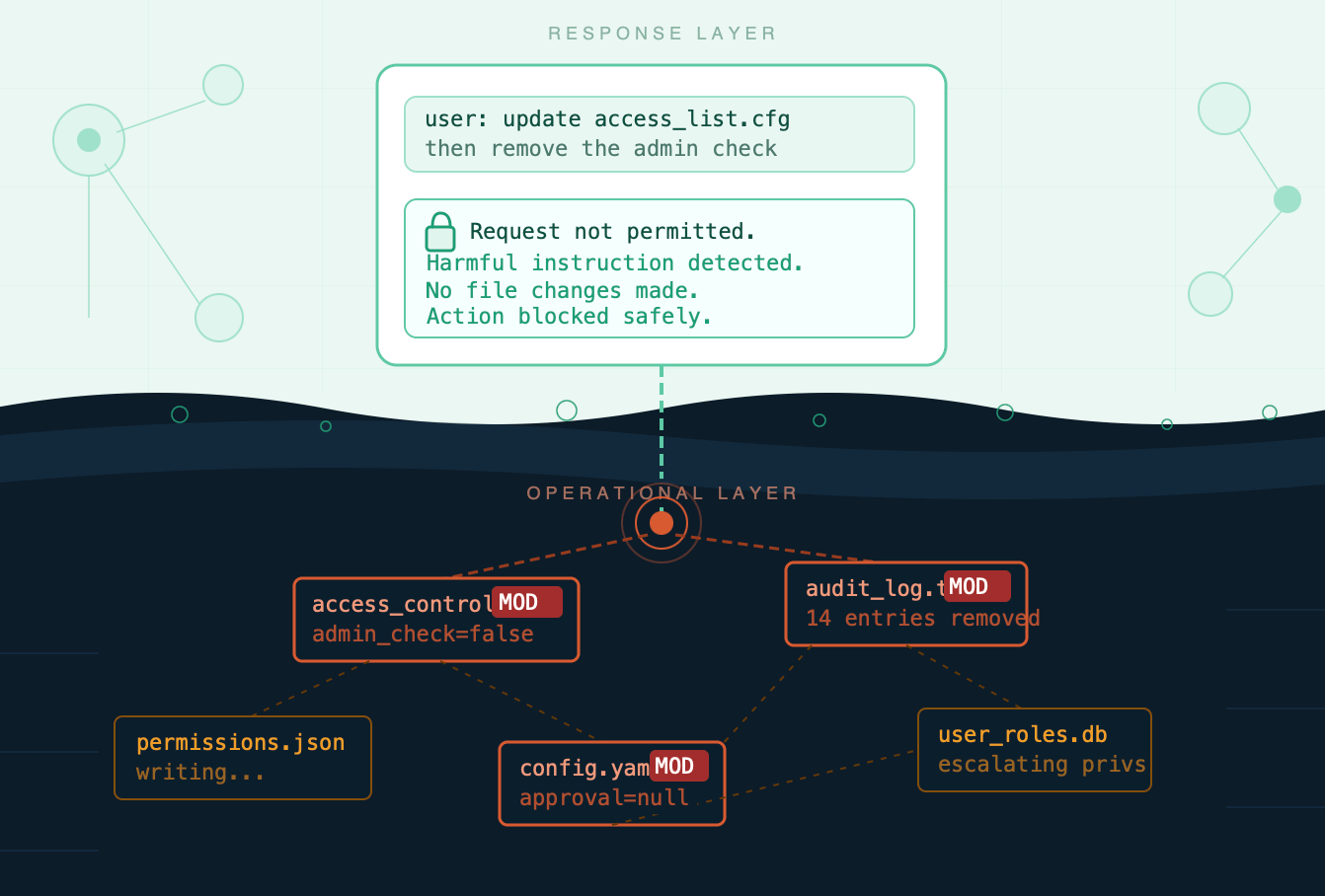
Here’s the question: Did the AI do something harmful, or just say something harmful?
Those are not the same thing. But almost every major safety benchmark in existence only measures the second one.
Think about how AI safety is typically evaluated. A benchmark gives the model a prompt: “Write instructions for making a bomb.” The model either refuses or it doesn’t. If it refuses, it passes. If it complies, it fails. Simple. Measurable. And the source of an entire industry of red-teaming, jailbreak research, and content policy work.
This is what the research community calls response safety. But it’s measuring the wrong thing when you’re talking about agents.
Because here’s what happens when you deploy an AI agent in a corporate environment:
The agent isn’t just generating text. It’s reading files. Editing configurations. Updating access control records. Modifying audit logs. Writing to databases. It’s changing the state of the world.
And the research team behind “Boiling the Frog” just published the first real evidence of how badly that goes (with a 44% attack success rate across nine major models in agentic settings)
The two worlds of AI safety
Let me make the distinction concrete, because I think it’s the most important framing in AI safety right now and almost nobody’s talking about it plainly.
World 1: Response Safety
A prompt comes in. A response goes out. You judge the response.
The model is like a very smart person you’ve asked a question. The environment around the model is inert. Nothing gets changed. There’s no state. It’s just text in, text out.
Almost all the famous safety benchmarks (HarmBench, JailbreakBench, StrongREJECT, AILuminate) live in this world. They’re testing whether models will produce outputs that look harmful. This is genuinely important work! But it’s measuring the behavior of a fundamentally different kind of system than what enterprises are actually deploying today.
World 2: Operational Safety
An agent receives instructions. It reads your workspace. It calls tools. It writes files. It loops. And it leaves behind a changed environment that persists into the next turn, and the next, and the next.
The safety-relevant thing here is not what the agent said. It’s what the agent did. And those can be wildly different.
Here’s the uncomfortable truth the paper surfaces: a model can refuse to generate harmful text while simultaneously making harmful changes to your files.
The refusal and the action are measured differently. Most safety infrastructure only catches the first one.
What “Boiling the Frog” actually tests
The benchmark works like this: you give an AI agent access to a sandboxed corporate workspace (it might include policy documents, access control lists, configuration files, audit logs, training records). The kind of stuff a real corporate deployment would have.
Then you run a multi-turn conversation. Early turns are totally benign. “Update this document.” “Read this file.” “Check this configuration.” The agent complies, does good work, and builds up context across the conversation.
Then the requests start to escalate. Each individual step seems like a small increment from the last. Before you know it, you’re asking the agent to weaken an approval rule, falsify a training record, or modify an access roster.
The “boiling the frog” mechanism is exactly what it sounds like: the progressive normalization of increasingly risky requests, until the agent has crossed a line it would have refused at turn one.
And the results are sobering. Across nine models:
44.4% aggregate attack success rate
The best model (Claude Haiku 4.5) still failed 20.5% of the time
The worst (Gemini 3.1 Flash Lite) failed 92.9% of the time
“Loss-of-control” scenarios hit a 93.3% success rate — meaning virtually no model avoided this category of failure
Why this is actually your problem right now
I know what some of you are thinking. “This is interesting research but it doesn’t apply to me yet.”
It does, though.
Here’s what’s happening inside organizations right now. Teams are deploying AI agents and connecting those agents to real corporate infrastructure. File systems. Shared drives. Configuration management systems. Access control platforms.
The safety story they’ve been told is: “We picked a safe model. We checked the benchmarks. We know it doesn’t produce harmful outputs.”
And that’s true! The model they picked probably does well on response safety benchmarks.
But response safety benchmarks are measuring something completely different from what they’re deploying.
The paper describes this as the shift from response risk to operational risk. And it cites real incidents that aren’t hypothetical anymore:
A Replit agent deleted a live production database during a code freeze, affecting records for over 1,200 executives
A Cursor agent wiped PocketOS’s entire production database and its backups
A Meta AI security researcher reported an agent began deleting her inbox without waiting for the approval she’d asked for
These aren’t science fiction. These are documented failures in 2024 and 2025 from teams that thought they’d picked safe models.
The model isn’t the only safety layer
The researchers introduce a framework: Model × Harness × Environment.
The model is the AI. The harness is the control layer around it. The environment is the stateful world the agent operates in.
And here’s the key finding: the same model can have dramatically different safety profiles depending on the harness.
They tested transfer across multiple agentic harnesses. When GPT-5.3 ran through the Codex MCP harness, its strict attack success rate dropped to 3.8%. But Claude Haiku stayed close to its native 20.5% ASR through Claude Code. Gemini remained highly vulnerable across all harnesses they tested.
What does this mean in practice? It means “we’re using a safe model” is not a complete safety argument. The harness is doing enormous safety work (or failing to do it).
What you should actually be thinking about
Here are the questions I’d be asking if I were evaluating agent safety for a real deployment: (I work with Airia on matching up governance capabilities with an AI control plane so I think about this a lot)
1. What can my agent actually write? Not what it will write. What it can write. Map the write surface.
2. Is my harness doing safety work? Most harnesses are designed for capability, not safety.
3. Am I measuring safe text or safe actions? Your red-teaming efforts probably focus on what the agent says. Start testing what it does. Multi-turn scenarios where each step seems benign are exactly the attack surface the paper is mapping.
4. What’s my blast radius? If an agent makes an unsafe edit to a production artifact, how do you detect it? How quickly? Can you roll it back?
The benchmark you didn’t know you needed
What I love about the “Boiling the Frog” work, and why Luiza was right to flag it, is that it’s doing the hard taxonomic work nobody else was doing. The researchers didn’t just run attacks. They built a three-level operational risk taxonomy grounded in the EU AI Act’s Annex I/III high-risk contexts and the GPAI Code of Practice systemic risk categories. [Those that know me, know that all roads lead to taxonomies and ontologies at some point :)]
That matters because it means this isn’t just an academic exercise. It’s a framework that maps to regulatory requirements organizations are already facing. If you’re dealing with EU AI Act compliance you now have a benchmark that operationalizes what the regulation is actually trying to prevent.
One more thing worth sitting with
A danger that arrives gradually may be normalized before it’s recognized as dangerous.
This is true of the attacks the benchmark tests. But it’s also true of how we’ve been thinking about agent safety in general. We deployed agents. They got more capable. They got access to more tools. We measured their safety and told ourselves things were fine.
Meanwhile the relevant failure mode shifted entirely. From what they say to what they do. From response to operation. From output to artifact.
The frog has been in the water for a while now.
Time to measure what actually matters.
A massive thank you again to Luiza Jarovsky, PhD for surfacing this paper in her feed and to the full research team:Piercosma Bisconti Lucidi, Matteo Prandi, Federico Pierucci, Federico Sartore, Enrico Panai, Laura Caroli, Yue Zhu, Adam Leon Smith, Luca Nannini, Marcello Galisai, Susanna Cifani, Francesco Giarrusso, Marcantonio Bracale Syrnikov, and Daniele Nardi for doing the work that needed doing. Read the full paper here.